
Business
Sustainable Machine Learning in the Software Industry
By IWA, 07.08.2019
Sustainability is not only about climate change, feeding the poor, and saving plants and animals. It is really about making conscious and educated decisions about how to design the future. Machine learning (ML) and artificial intelligence (AI) have been surrounded by lots of hype recently. These technologies are playing a big part in the architecture of many modern products and services. Engineering sustainable digital systems is more important than ever. As we start outsourcing decisions and design to machines, it is important to understand their capabilities and downfalls.
This article is about understanding ML at a general level, and aims to highlight some basic points that developers and designers (and, well, everyone) should be aware of, now that ML has already moved out of the research labs and into our pockets.
Why is everything suddenly AI?
There is not one precise definition for AI, and that can create a lot of confusion. In general, artificial intelligence is based on the idea that thought and reasoning can be mathematically mechanised. Whether or not we will recreate the human thought process precisely is anyone’s guess. Today we use digital systems to expand what we can know and do in the world. Computers are often very good at narrow sets of intelligent tasks (narrow AI), and they can also be good at seeming intelligent given the right data (weak AI, see the “Chinses room argument” for more about this). Despite that, humans still rule in things like understanding cultural contexts. Current applications of AI augment our intelligence but they don’t recreate or replace it.
Why we should talk about machine learning
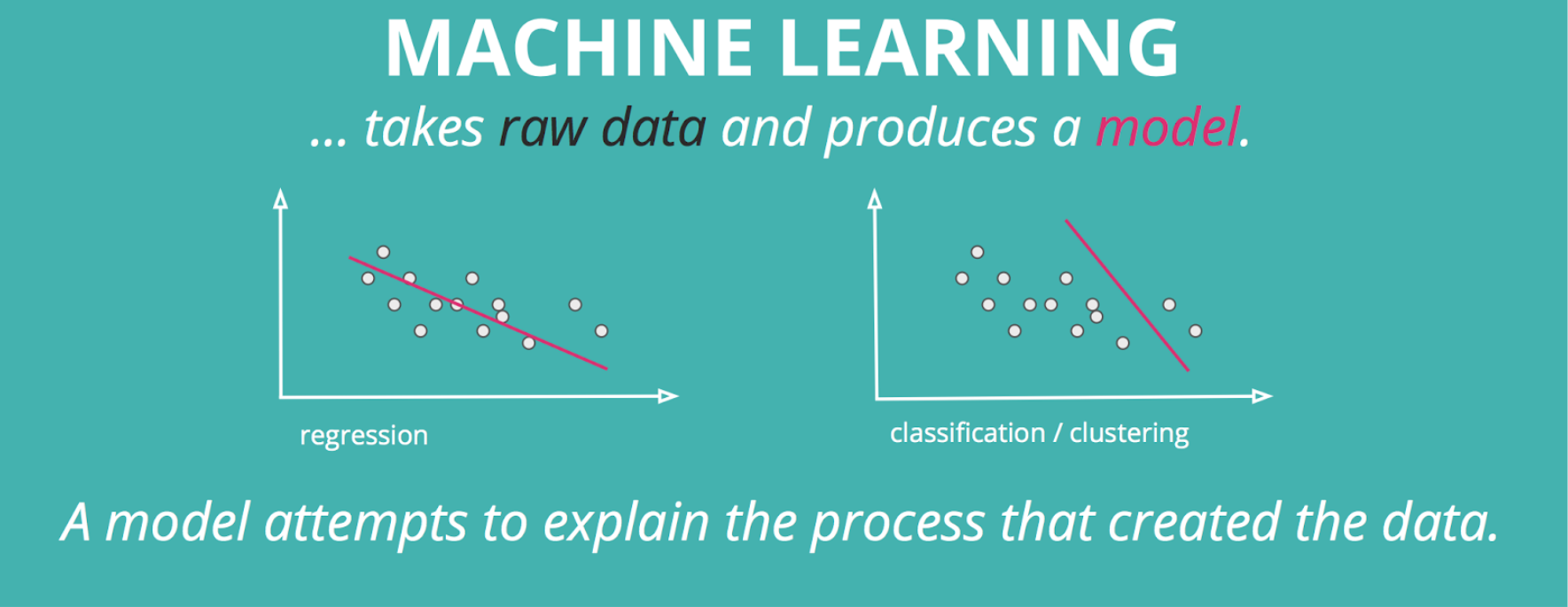
Machine learning is a subfield of AI in which algorithms “learn” things about the data they are given. This process is called training, in which an algorithm takes in raw data and produces a model. A model attempts to explain the process that created the data. The model can then be applied to new observations to estimate something that we want to know about the context of that data.
The most common areas for applying machine learning today are image recognition, natural language processing, recommendation systems and outlier detection. Some interesting uses of ML are also appearing in the fields of art, music, UI design, smart energy systems, and health & wellness.
The vast availability of data and advances in computing power are the reasons why ML finally broke through, after decades of academic study.
However, machine learning is not only about big data. An important field of machine learning that is gaining traction aims to analyse and extrapolate patterns in situations where there are only very little data available.
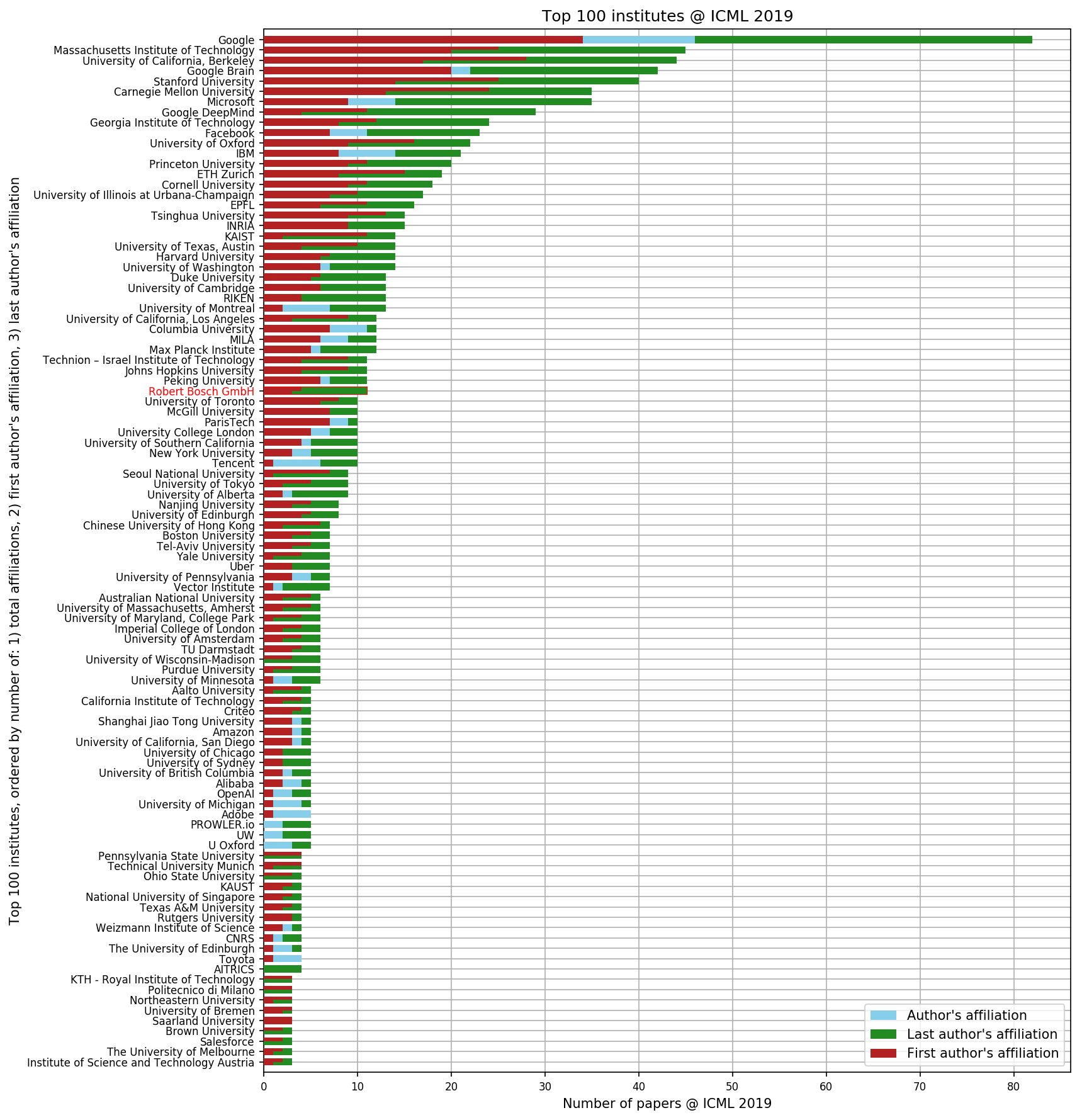
Industrial manufacturing has caught onto machine learning big time. Almost one quarter of the contributions to the International Conference for Machine Learning (ICML) this year came from industrial affiliations (that’s a lot).
Machine learning can be very useful to deepen our understanding of the world around us and to automate tasks, allowing us to focus on more interesting ones. But we have to be careful when outsourcing some of our decisions to computers. Here are two important things to consider: 1) the quality of the data, and 2) the interpretability of the model.
Sustainability of decisions depends on the quality of data
Quality data is the foundation of good machine learning. “Garbage in, garbage out” is a popular expression in data science and ML. Basically, the data should represent the process or state that we are interested in. Training a model with cat and dog pictures and then asking it to classify court cases wouldn’t make much sense. But there is also a subtler danger that we should consider: the fact that data is always biased in one way or another. For example, even data collected in the recent past may not reflect societies’ current values.That is why we should be very diligent when sourcing data for ML applications, and understand the difference between what we want to know and what the data is able to tell us.
How black is the box — or the interpretability of the model
Machine learning methods, specifically deep learning, have become highly adaptable to different kinds of data and can produce astonishing results. However, higher flexibility in this field generally comes with the cost of lower interpretability.

Interpretability is important because we want to be able to understand how the model generated its estimations. When this is very ambiguous, the model is a so-called black box. As we more often rely on complex interpretations of the world made by machines, the need to understand “why is this true” becomes more pronounced in order to justify the numerous decisions that are based on the output of ML algorithms. An example of this is an image classifier that was correctly classifying dogs based on the features of the background of the photo rather than the features of dog itself. Sometimes things seem right, but there are many applications in which “seeming right” is not good enough.
How to design machine learning systems
A good starting point for designing machine learning systems includes asking the following questions:
- What do we want to know?
- What can(‘t) we entrust the algorithm to decide?
- What data do we have, and what is it able to tell us?
- Who is going to be using the system?

Who’s leading the charge?
Progress in machine learning is rapid, and ML is already a part of many staple consumer products. Designing the future is not only the responsibility of researchers and philosophers. It’s everyone’s responsibility: from developers, designers and business owners to anyone who interacts with technology. So if you are reading this, that includes you!